What is the purpose of this user manual?
This user manual provides an overview of the information contained in the ToscanaOpenResearch dashboard and aims to present to an audience without specific expertise how to consult and access data on Research, Innovation and Higher Education in Tuscany.
With the aim of increasing the usefulness and extending the use of ToscanaOpenResearch, this document describes the project behind this portal, highlights the richness and variety of the data it contains and illustrates how the system can be interrogated to obtain the desired information.
For any comments or questions regarding ToscanaOpenResearch, please send an e-mail to the following address: staff@toscanaopenresearch.it.
What is the project ToscanaOpenResearch?
In the context of its Regional Observatory for Research and Innovation, established by Regional Law 20/2009 in order to have a qualified knowledge base and an information tool to support policies, the Region of Tuscany has created ToscanaOpenResearch (TOR) with a dual purpose:
- To communicate and enhance the ecosystem of higher education and regional research, promoting an increasingly transparent and inclusive governance;
- Analyzing the ecosystem of higher education and regional research in order to start a process of orientation of regional policies in a data-driven perspective.
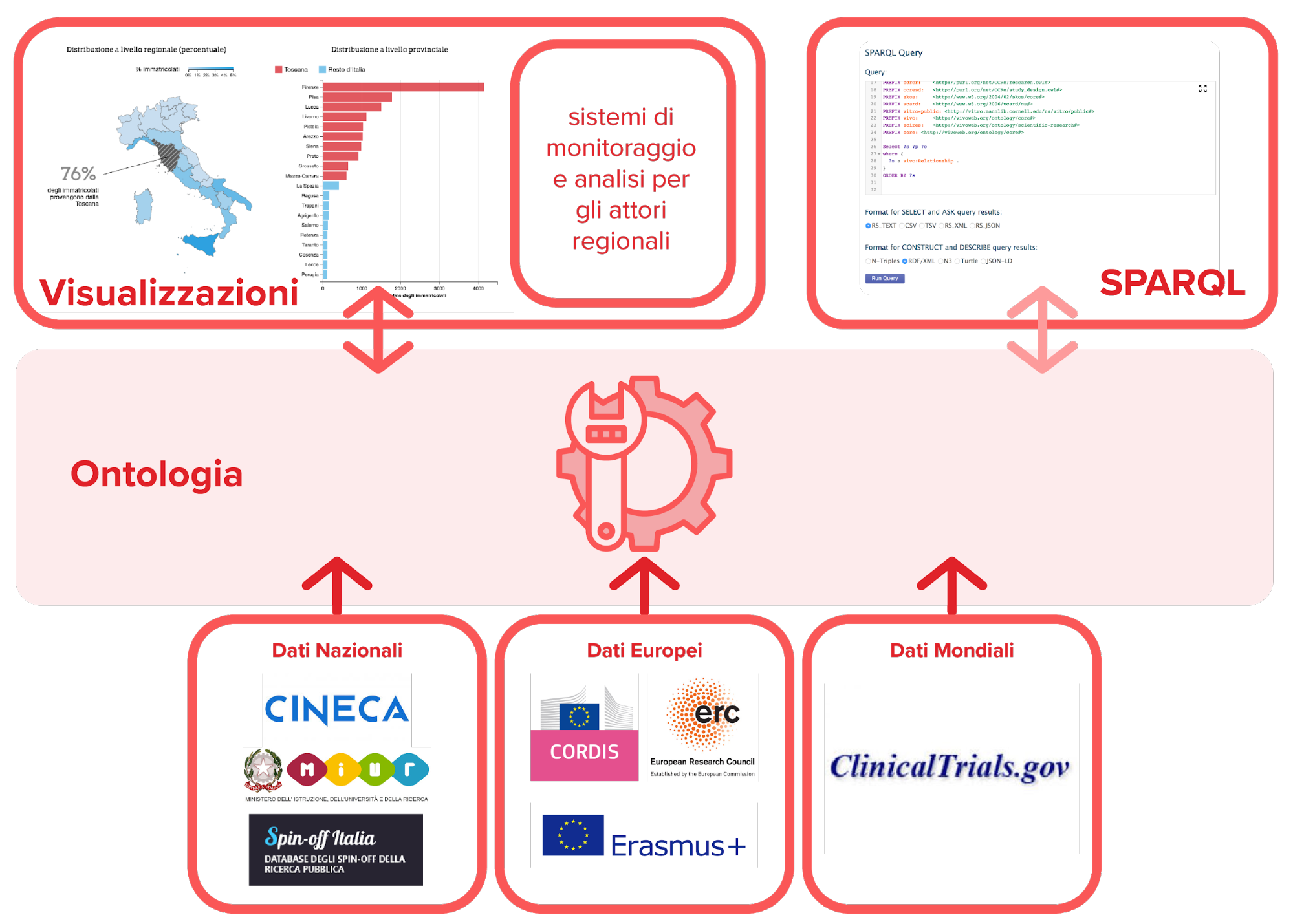
TOR therefore represents the Observatory's information tool, and is made up of different components:
- various data sets on research, innovation and higher education: the data are presented in detail in the sections “What data is available on ToscanaOpenResearch?” and “What data can be explored on TOR?”;
- a domain ontology, presented in the section “The TOR ontology”;
- a SPARQL endpoint to explore and download data, presented in the “What is SPARQL Endpoint and how does it work?” section;
- interactive visualizations that answer questions about higher education, research and innovation and research collaborations in Tuscany. The visualizations allow to easily explore the data and directly download the data displayed in CSV format, and are presented in the section “What is the origin of the visualizations?”.
The ToscanaOpenResearch components are presented schematically in the figure below:
What is the origin of TOR visualizations?
The TOR dashboard, the “Explore The Data” section that hosts the visualizations, is built with open source technologies.
The views are based on data directly retrieved through the SPARQL Endpoint. Therefore, each time the data is updated, the views will also update automatically.
The views that appear on ToscanaOpenResearch in the “Explore The Data” section have been created to answer the questions produced by the Regional Conference for Research and Innovation through a co-design process developed in 3 sessions between 2017 and 2018.
The Regional Conference for Research and Innovation is a permanent collegial structure with advisory functions, that gathers representatives of universities, research centres, science and technology parks, companies and trade unions. In this regard, during the initial phase of the Pilot Dashboard, several questions had emerged.
Among the questions posed by the Regional Conference, which were answered through interactive visualizations in the portal, we find:
-
Mapping of the PhD courses
An overview of PhD courses in Tuscany is outlined by these two views: the first one shows the number of students enrolled and graduates to PhD courses in Tuscany, by year and by university; the second one, provides information about students enrolled and graduates to PhD courses, by year, university, gender and title of the PhD.
-
Mapping of Master's courses
To answer this question, ToscanaOpenResearch includes two views: the first one the first one shows the number of students enrolled and graduated in Masters in Tuscany by year and by university, taking into account both first and second level Masters; while the second one shows the number of students enrolled and graduated in Masters in Tuscany by university, gender and title of the Master.
-
Overview of public research spin-offs in Tuscany
This visualization has been created, which shows the collaborations of Tuscan actors on research and innovation projects with European funding, both with Italian and international collaborators. The map allows to filter by type of program, by country collaborator and by type of activity.
-
A general overview of the collaboration networks that emerge from the analysis of European-funded research and innovation projects
To answer this question, a visualization has been created, which shows the collaborations of Tuscan actors on research and innovation projects with European funding, both with Italian and international collaborators. The map allows to filter by type of program, by country collaborator and by type of activity.
For each of the above mentioned visualizations, as for all those present inside the portal, it is possible to download directly the data represented inside the visualization, in csv format, by clicking on the red arrow just below the representation.
What data is available on ToscanaOpenResearch?
The open data on ToscanaOpenResearch is the result of the integration of numerous databases, memorandum of understanding and data from bibliometric databases.
In particular,
- data from regional, national, European and global open databases is available;
- a number of additional data have been integrated through memorandum of understanding (e.g. Ministry of Education, University and Research - MIUR, for the integration of data related to National Technological Clusters - CTN 2012 and 2016 and to Research Projects of Significant National Interest - PRIN 2012);
- or the publications part, the system uses non-open bibliometric databases, but is already prepared for easy integration with CINECA-IRIS data.
The system currently focuses on the Tuscan perimeter, but for most of the data the national perimeter has already been integrated, and it is therefore possible to carry out context analyses at national or even European level (in the case of research projects).
What data can be explored on TOR?
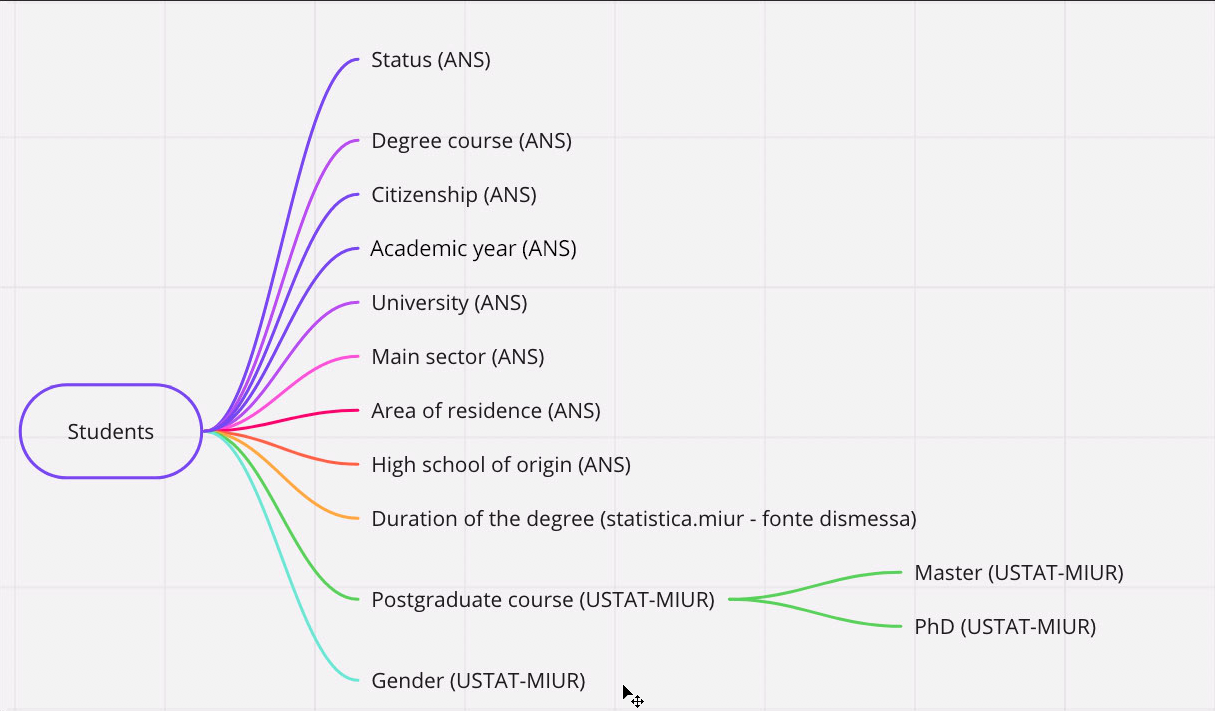
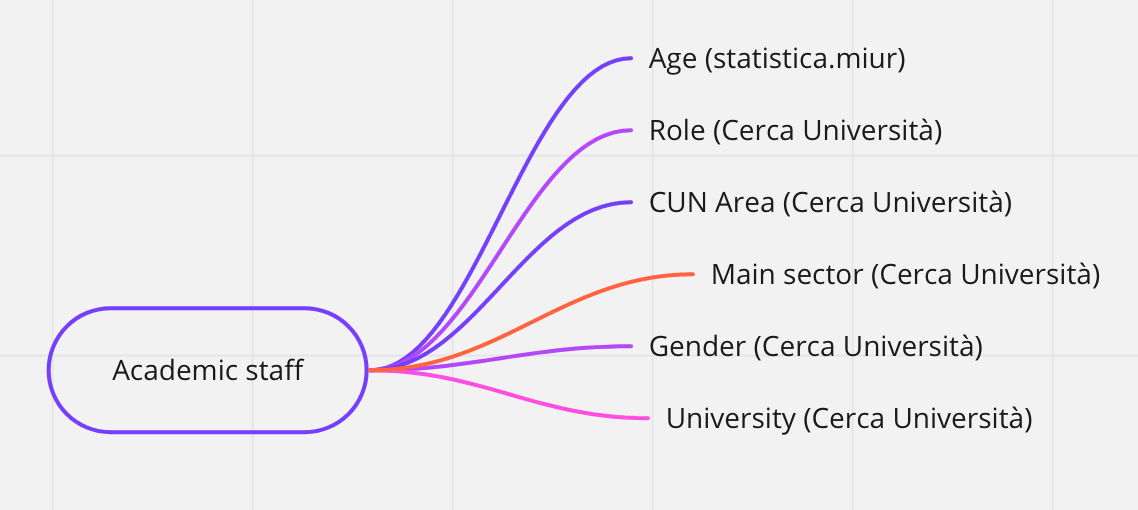
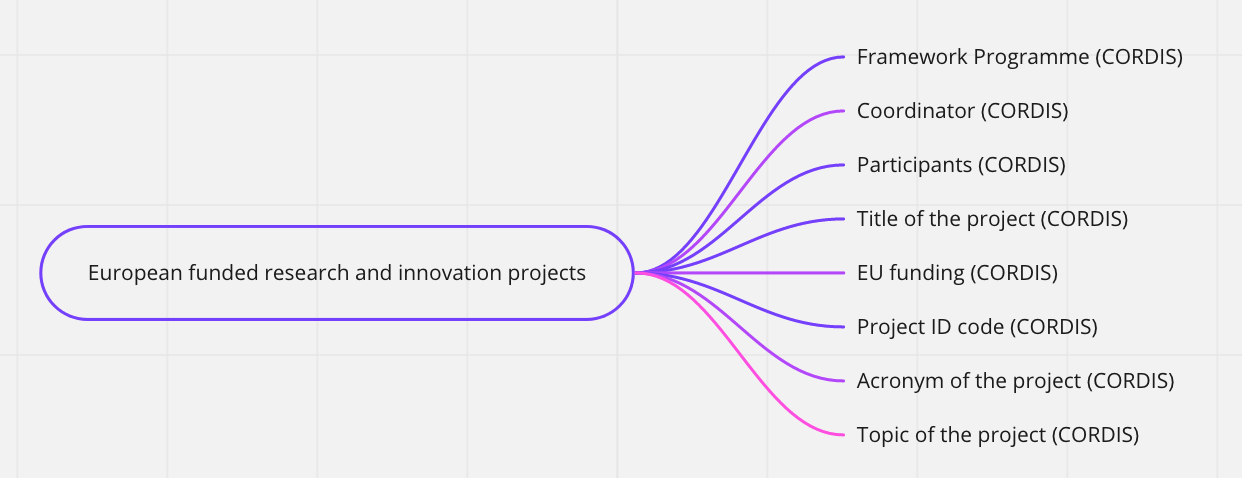
In this regard, the following "mind maps" offer a cross-section of the information available depending on the subject or topic of interest.
-
Subject/Topic:
- Students
- Academic staff
-
Projects
- European
- Italian (CTN, PRIN 2012)
- Erasmus+
- CHAFEA
- Spin-off
- Clinical trials
- Data on the right to study
- Data on gender balance
A simplified view of data via mind map
The idea of the “mind maps“ represented below is to outline a general picture of the data available on ToscanaOpenResearch, by topic.
Indeed, the word in the middle of each map (inside the box with the rounded border) represents the subject of interest, the subject from which it is possible to obtain the information indicated by each arrow.
The source of the data is reported in brackets, with the exception of the CTN/PRIN 2012 data, which were obtained through a memorandum of understanding between the MIUR and the Region of Tuscany.
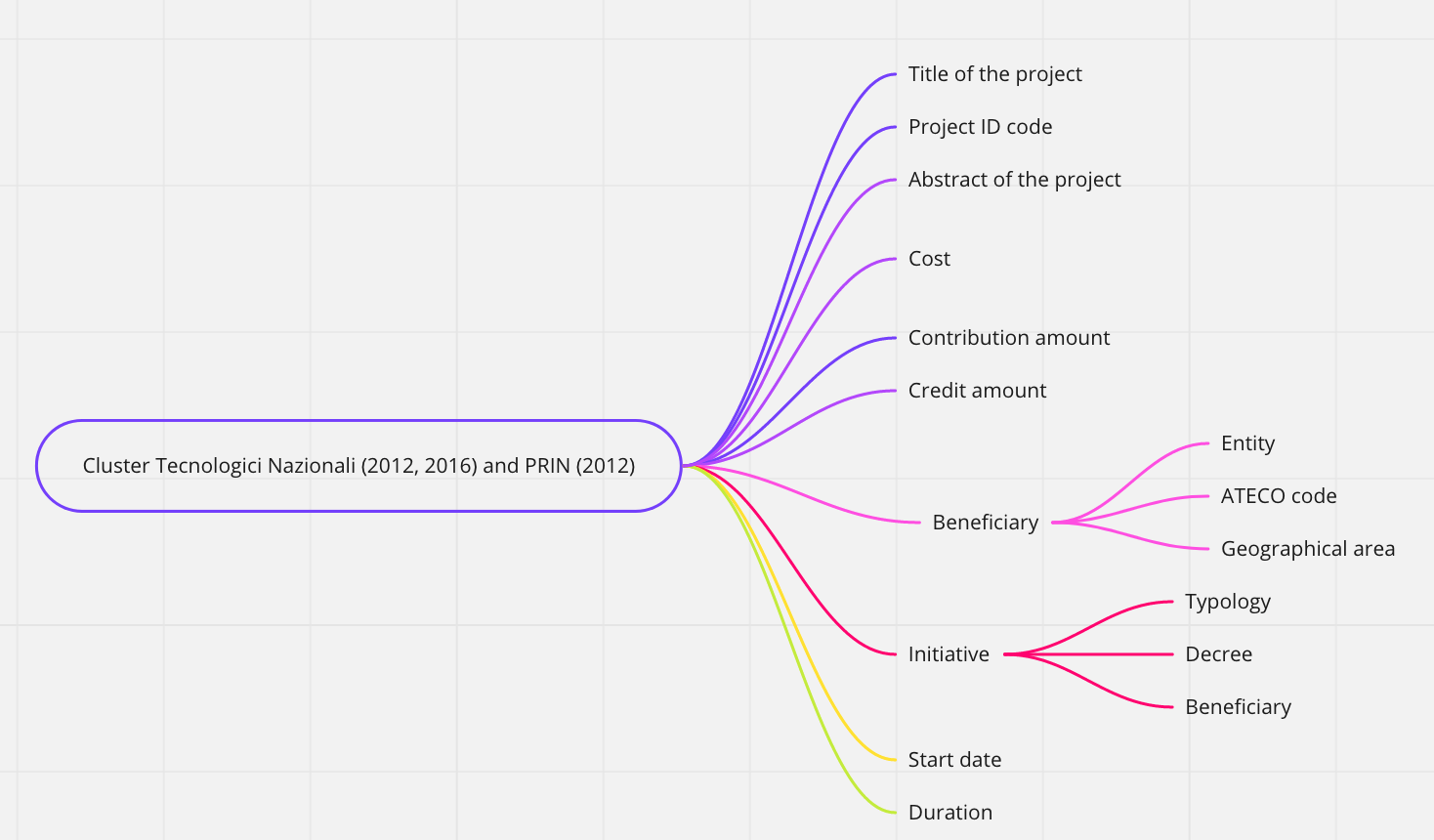
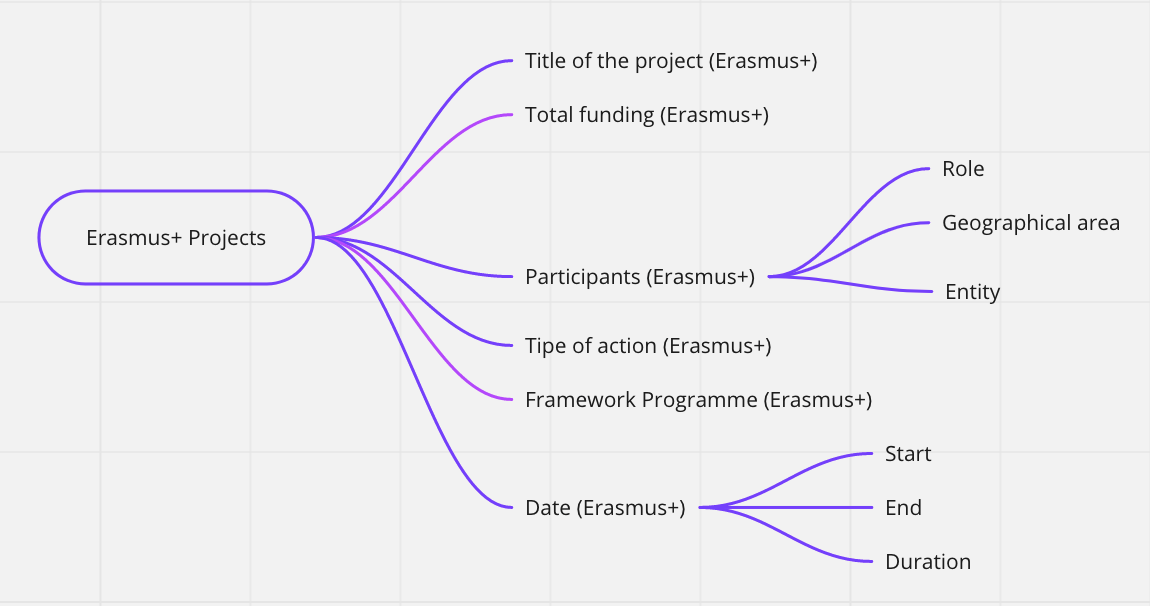

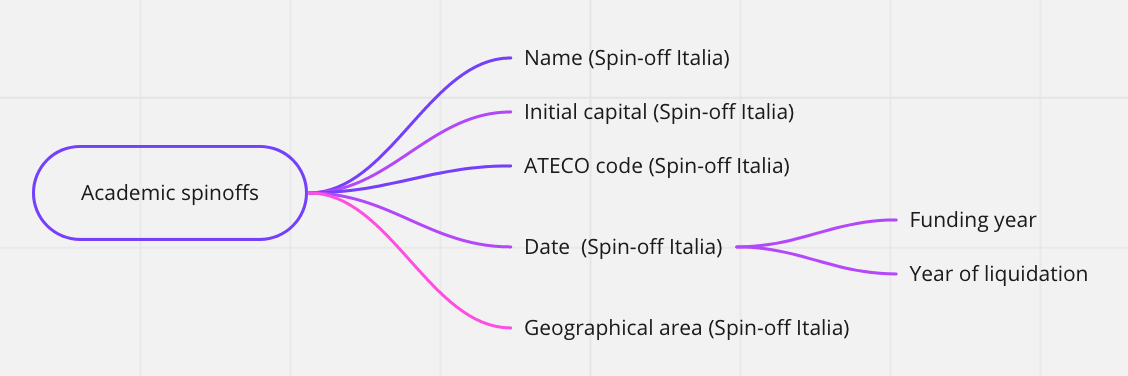

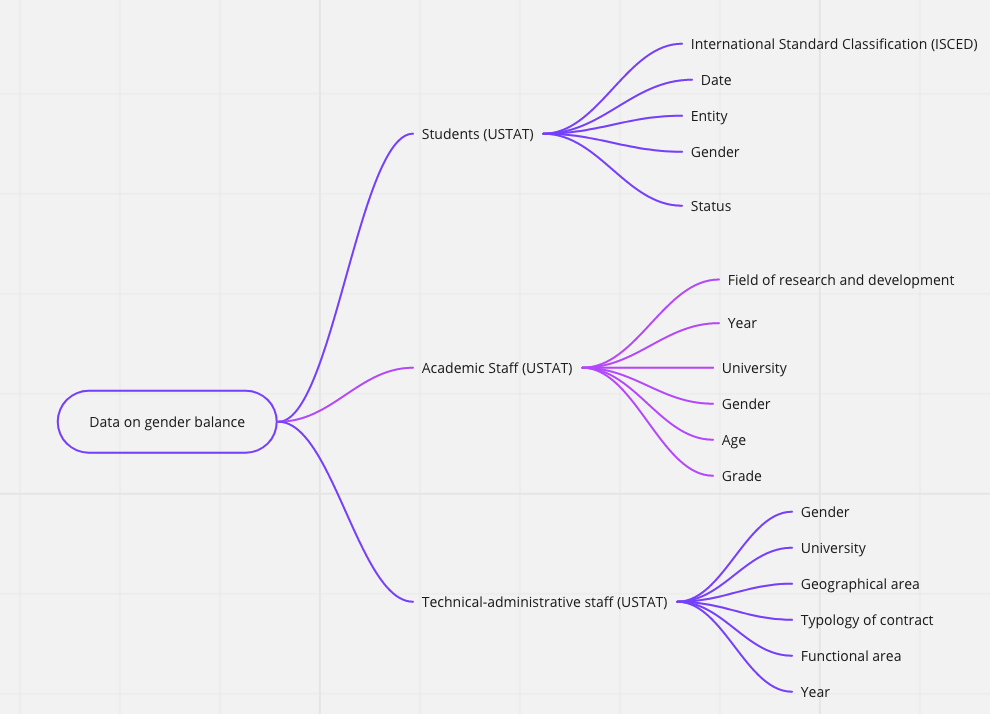
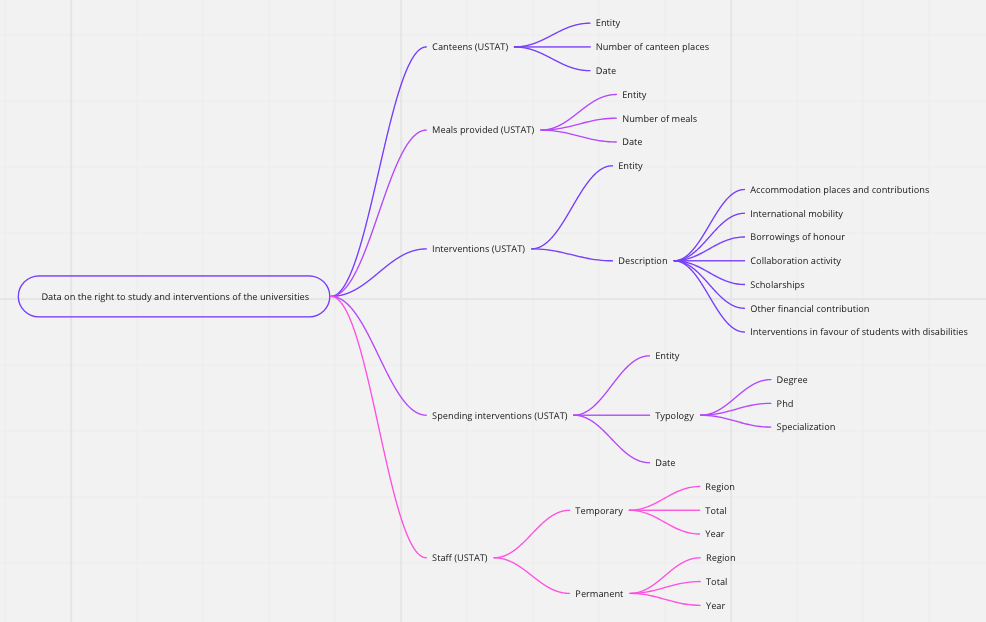
However, the mind maps above offer only a general idea of the data available for each concept and/or subject. We will now see how to analyze in more detail the available data and how to consult them through an ontology, that is a formal, shared and explicit representation of a conceptualization of a domain of interest.
How to query the data?
This section provides an introduction to the SPARQL Endpoint, the technology used to query TOR data, and to the ontology charts - graphical representations that allow to describe entities (objects, concepts, etc.) and their relations in a given knowledge domain - in order to make the reader autonomous in querying the data of the Observatory.
What is the SPARQL Endpoint and how does it work?
The SPARQL endpoint allows users to retrieve data using the SPARQL query language, which is a standard defined by the World Wide Web Consortium (W3C). The SPARQL endpoint can be used by both human users and machines. Humans interact with it through a graphical user interface, while machines (scripts, applications, etc.) communicate with the endpoint using the standard SPARQL protocol defined by W3C.
Data retrieved from a SPARQL endpoint complies with the Linked Data Linked Data approach to publish data in the Semantic Web context. This means that the data format is RDF (Resource Description Framework), (Resource Description Framework), where the information is represented as resources. Each resource is identified by a Uniform Resource Identifier (URI), which in most cases resembles a web address (e.g. http://unics.cloud/ontology#Project-123). Resources are characterized by properties. Some properties attribute data values to a resource, such as the acronym of a project or its title, while others link a resource with another resource, such as a project with one of its participants. Properties that attribute data values are called "data properties", while properties that link resources are called "object properties". Properties, like resources, are identified by URIs (e.g. http://unics.cloud/ontology#acronym).
Conceptually, Conceptually, data formatted in RDF is a graph, where nodes are either resources or data values, and links between nodes are either data properties or object properties. In practical terms, however, RDF-formatted data is normally represented as a list of triples. A triple is a phrase in the form of a "predicate object subject". These triples are used to list links in the graph, i.e. the subject of a triple is always a resource, the predicate is a property, and the object is either a data value or another resource. As an example, a data set containing two projects of the same call with their title and abbreviation would look like this (URIs are often written in angular brackets):
<http://unics.cloud/ontology#Project-1> <http://unics.cloud/ontology#acronym> "Acronym 1"
<http://unics.cloud/ontology#Project-1> <http://unics.cloud/ontology#title> "Title 1"
<http://unics.cloud/ontology#Project-1> <http://unics.cloud/ontology#call> <http://unics.cloud/ontology#Call-A>
<http://unics.cloud/ontology#Project-2> <http://unics.cloud/ontology#acronym> "Acronym 2"
<http://unics.cloud/ontology#Project-2> <http://unics.cloud/ontology#title> "Title 2"
<http://unics.cloud/ontology#Project-2> <http://unics.cloud/ontology#call> <http://unics.cloud/ontology#Call-A>
<http://unics.cloud/ontology#Call-A> <http://unics.cloud/ontology#name> "Name of call for projects A"
In RDF and SPARQL it is common to use prefixes to shorten resource and property names, i.e. URIs. As we see in the previous example, all resources and properties of this dataset have URIs starting with "http://unics.cloud/ontology#". To avoid writing this common part each time, we can define an abbreviation for this prefix, for example "tor:", and write this abbreviation instead of the full prefix. The above example would become then:
Prefix tor: <http://unics.cloud/ontology#>
tor:Project-1 tor:acronym “Acronym 1”
tor:Project-1 tor:title “Title 1”
tor:Project-1 tor:call tor:Call-A
tor:Project-2 tor:acronym “Acronym 2”
tor:Project-2 tor:title “Title 2”
tor:Project-1 tor:call tor:Call-A
tor:Call-A tor:name “Name of call for projects A”
In terms of syntax, the abbreviation of a prefix must be in the form of "name:" (note the ":" at the end). The shortest possible abbreviation is the one where "name" is empty, i.e. the abbreviation is just ":". Also, note that when abbreviations are used for prefixes, URIs are no longer written in angular brackets (these are only used for non-abbreviation URIs).
In order to write queries on RDF data using the SPARQL language, you need to know which properties can be applied on which resource sets. This is where ontologies come into play.
An ontology is essentially a definition of the structure of data formatted in RDF format, where resources with similar properties are grouped into concepts (also called classes). In this sense, an ontology defines a set of concepts (e.g. Project, Call, Participant, Country, ...) and a set of properties (both data and object properties) that can be applied to these concepts. Concepts, just like properties and resources, are identified by URIs (which can be abbreviated as seen above).
TOR Ontology
For data integration the system uses Ontology-Based Data Access (OBDA) approach, which allows data integration through a domain ontology and allows users to access data by queries, eliminating the need to know the technical terms related to the physical organization of the databases and the internal structure.
The documentation of the ontology is available on the ToscanaOpenResearch website, in the section Data Access> Ontology documentation, at the link: http://toscanaopenresearch.it/sparql-endpoint/en/docs/index.html.
How to read the Ontology diagram?
In the diagrams, the boxes with rounded borders indicate the concepts, , with the list of names written inside each box, which are the given data properties applicable to thiat particular concept. For example, in the TOR ontology part of CORDIS projects, the "Organization" concept has the data properties "unicsId", "extendedName" and "acronym". The arrows with open tip between the boxes represent object properties. The name of an object property is indicated by a label on the arrow, and the application direction of the property is given by the direction of the arrow itself. For example, the arrow labeled with "principalInvestigator", which links the "EC-Project" concept with the "Person" concept, represents an object property that associates to a European project the person who is the principal investigator of that project.
To each given property and to each object property is associated a cardinality constraint, specified through a "min..max" pair, which establishes a limit to the minimum and maximum number of values that the property in question can have. For example, the "0..1" constraint on the "principalInvestigator" property indicates that an object in EC-Project (i.e., a European project) may or may not have a principalInvestigator (minimum constraint 0), and in any case may have at most one (maximum constraint 1). Similarly, the "[0..1]" constraint on the given "startingYear" property of "EC-Project" indicates that a European project may or may not have a single starting year. In general, the minimum cardinality can be 0 (i.e. no minimum constraint), or a positive integer; the maximum cardinality can be a positive integer, or "n" (i.e. no maximum constraint). If the cardinality constraint specification is missing in the diagram, "1..1" is assumed, i.e. the property is both mandatory (it always has a value) and functional (it has only one).
Another important element of ontologies is the generalization mechanism, which allows concepts to be organized in one or more hierarchies. A generalization (also called “is-a”), A generalization (also called "is-a"), is indicated in the diagram with an arrow ending with a closed triangle, which goes from a more specific concept to a more general one. An is-a indicates that each object that belongs to the more specific concept also belongs to the more general concept. For example, the arrow is-a from "ERC-Project" to "EC-Project" indicates that each ERC project is also a European project. By virtue of this, generalization implies inheritance, i.e. the fact that a more specific concept inherits all the properties of a more general concept. For example, every ERC project, being also a European project, has all the properties of European projects, e.g. a title. But an ERC project also has additional properties that European projects in general do not have, for example the fact of having an "ercGrant".
Focus - The benefits of data access based on domain ontologies
The Ontology-Based Data Access (OBDA) approach, also called Virtual Knowledge Graph, allows to access relational databases and data sources of different nature (e.g. CSV files, excel tables, JSON data) mediating these accesses through a domain ontology. This ontology provides a consolidated data model, shared between different actors, and expressed using domain-specific terminology and concepts, which can also go beyond what is present in specific data sources. The ontology is then linked to the sources using declarative “mappings”. These make explicit the way the connection is made, and do not "hide" it in programmatic code, as happens in traditional integration systems. The user can then extract the information of interest, using terms familiar to him/her from the ontology. He can easily formulate even complex queries directly on the ontology, without the need to know the terms used in the different source databases, often cryptic and difficult to understand, or how the data are organized there. The user query is then translated into appropriate accesses to the data sources and the answers are combined to provide the answer to the user, using the ontology itself and the mapping. This is done in a completely automatic and transparent way to the user. The entire approach is based on standards defined by the World Wide Web Consortium (W3C) for ontology, mapping, and query language.
It is important to note that the ontology provides a unified view of data as a graph (set of linked elements) of knowledge.
On the one hand, this greatly simplifies the integration and reconciliation of data from different sources.
On the other hand, the ontology can be reused in different contexts where the domain is similar, simply by connecting new data sources.
In addition, data can be made accessible by focusing on who will then use it. This logic also includes the possibility to take into account in the data mapping only specific details that are of interest for certain types of users or in a certain context, and respecting criteria of privacy or confidentiality.
Ultimately, an OBDA system allows data to be used by a wider audience with less familiarity with specific sources. The use of OBDA systems typically does not require changes to the databases themselves, thus allowing the underlying systems to remain fully operational. In summary, the OBDA approach can be considered as a mechanism to provide a high-level API (Application Programming Interface) for heterogeneous data sources.
At the technological level, the ToscanaOpenResearch OBDA system uses Ontop, a particularly high-performance and advanced OBDA implementation, as also highlighted by specific scientific literature. This Open Source software boasts a heterogeneous user community, ranging from users operating in an industrial context to financial institutions and university research groups. The software is in continuous development, with the addition of new or improved features and the possibility of professional support in addition to that of the community.
The ontology developed within ToscanaOpenResearch is now being aligned with the national project OntoPIA (the network of public administration controlled ontologies and vocabularies), coordinated by AgID - Agenzia per l'Italia Digitale, to become the national reference ontology on higher education and research: the ontology is available at this link.
How to write queries to explore and download data?
After learning the basics of SPARQL Endpoint and the graphical representation of ontology, it's time to query the system and experiment with queries on your own.
A query to a SPARQL endpoint typically consists of the following keywords:
- PREFIX: used to specify the URL of the ontologies to be used in the query.
- SELECT: defines the output values that will be included in the query. These values must be present within the WHERE clause.
- WHERE: contains the information in the form of a restriction in order to obtain data.
Below is an example of a query that outputs universities in the UNICS ontology.
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#glt;
PREFIX unics: <http://unics.cloud/ontology#>
SELECT ?org
WHERE {
?org rdf:type unics:University .
}
The PREFIX instruction followed by a word (free choice) introduces an abbreviation for potentially long URLs. Returning to the example of universities, in the UNICS ontology universities are available through the URL “http://unics.cloud/ontology/University”, using the PREFIX instruction, you can refer to universities using "unics:University", since the URL of unics has been saved in the word unics.
Note that the query is divided into at least two parts.
In the first part, introduced by SELECT, you list the variables you want to have as a result,, separating them with spaces.
The second part, introduced by WHERE and enclosed by curly brackets, specifies the rules in the form of triple RDF. A triple RDF is composed of:
- Subject: indicates a resource available in ontology;
- Predicate: allows you to create a relationship between subject and object;
- Object: can be a resource identifiable by a unique URI or data.
In the example above we find:
- ?org: subject of the query
- unics:University: object of the query
- Rdf:type: predicate that allows you to save the content of the unics:University object in the variable ?org.
Analyzing the content of the query, you notice that you are asking for entities that are unics:University type. The term "org" is a variable in which the content is saved. It can take an arbitrary name, as long as it starts with a question mark. It allows you to use all the values it takes in the "valid" triples in the results table. Within a variable it is possible to save any type of content, be it data or URI that will be used later to create more complex queries.
Basically, WHERE selects data to be taken into account to build the results table.
You can insert more than one triple pattern in a WHERE clause:
PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
PREFIX unics: <http://unics.cloud/ontology#>
SELECT *
WHERE {
?org rdf:type unics:University .
?org unics:extendedName "Università di Firenze" .
}
To the previous example is added the condition that with the same subject of the first pattern and associated to the variable "University of Florence".
You can guess how queries can grow in complexity. In combination with SPARQL's feature of being able to query metadata ("what property can a university have?"), this makes it a very suitable language for progressive data exploration.
There are also several more refined ways to select and process data, for which reference is made to the more specific literature and examples contained on the TOR portals.
A library of predefined queries, organized coherently with the main sections of the Observatory, is available in the Data Access > SPARQL endpoint section at the following link: http://toscanaopenresearch.it/sparql-endpoint/en/.
Through this SPARQL endpoint it is also possible to obtain immediate visual processing of the data obtained from the execution of the queries, using tools such as "Pivot Table" and "Google Chart".
However, once you become familiar with SPARQL endpoint and the ontology diagram, following the instructions above, you can change the queries and adapt them according to your needs, adding more information and/or changing the perimeter (both temporal and geographical) of interest.